Research Scholar
Hoime Banerjee
Bioinformatics
About me
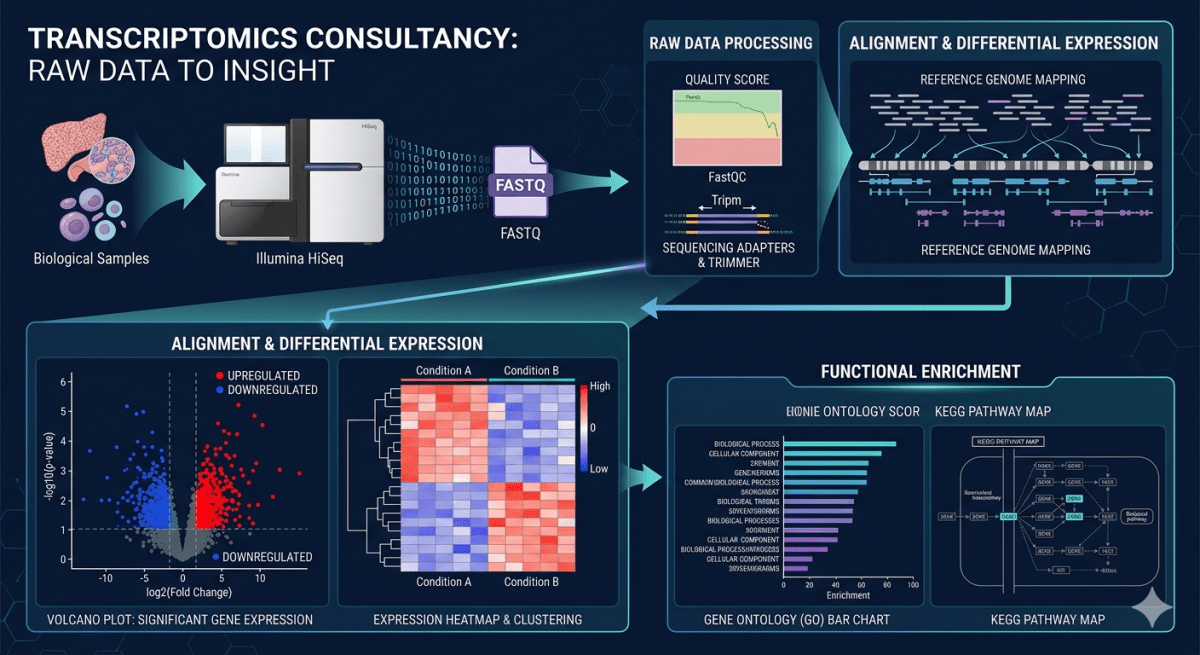
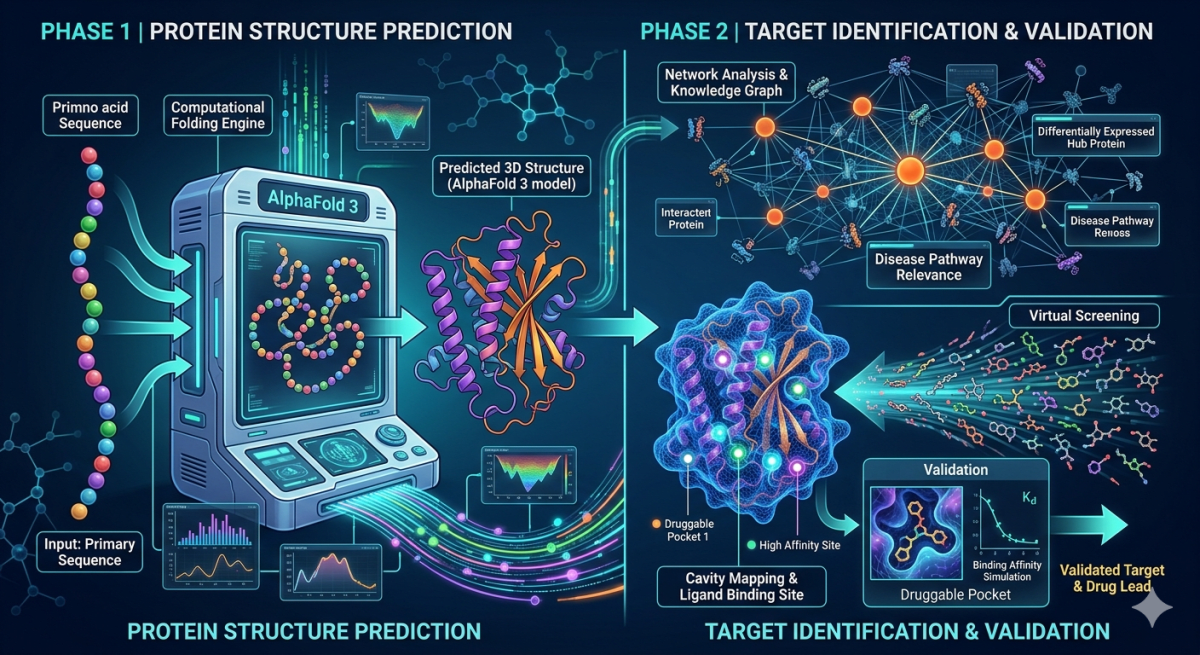
During PhD, I studied zebrafish brain development, focusing on a Tbox transcription factor involved in neural development. I mapped its spatial expression using in situ hybridization and identified expressing cell types with specific biomarkers. I analyzed RNAseq datasets to find downstream targets and performed motif analysis to predict regulation. I also overexpressed the factor in specific cells to assess its role in neural development. In my MTech, I have worked on protein purification.
Interests: My research interests focus on integrating experimental and computational techniques to study gene regulation and function. I am interested in spatial gene expression analysis, cell-type identification, and transcriptomic approaches such as RNA-seq. Overall, I aim to combine wet-lab and bioinformatic tools to understand how gene expression controls cellular identity.